
If you’re an entrepreneur, it’s probably already happened to you: you hire an AI solution that promises to transform your business and end up paying astronomical bills for each query, sending confidential customer information to servers you don’t control, and relying entirely on an outside company for something as critical as your business intelligence.
That era has just ended.
Google just launched Gemma 3n, and we at Montevive.ai know this isn’t just another technology upgrade. It’s the moment when enterprise AI truly becomes yours.
Why is everyone talking about Gemma 3n?
Imagine having all the power of ChatGPT running in your own office, processing your most sensitive documents without ever leaving your infrastructure, and without paying a penny extra for every question you ask.
👉 In fact, it is the sister model of JuntaGPT, another pioneering implementation already used by public institutions to preserve technological sovereignty.
Unlike other static models, Gemma 3n introduces a key innovation: dynamic weights, allowing it to better adapt to the context of use and optimize performance without the need for complete retraining.
This makes it an ideal solution for deploying directly to local devices – from laptops to high-performance servers – while maintaining privacy and efficiency at the highest level.
That is exactly what Gemma 3n makes possible:
Actual performance we have tested
At Montevive.ai we don’t just talk theory. We have tested Gemma 3n on our own servers and the results are impressive:
Gemma 3n (2.6B parameters) – Typical enterprise configuration:
- ⚡ CPU only: 19.8 tokens/second average
- 🚀 With GPU acceleration: 69.8 tokens/second average
- 📝 Proven cases: Corporate policies, technical reports, legal documentation
- ✅ Success rate: 100% in all tests
Gemma 3n (4.5B parameters) – For more complex tasks:
- ⚡ CPU only: 9.5 tokens/second average
- 🚀 With GPU acceleration: 51.7 tokens/sec average
- 📊 Superior quality for in-depth analysis and complex reasoning
| Model | Configuration | Tokens/s | Average response time (s) |
|---|---|---|---|
| gemma3n-2.6B | CPU-only | 19.79 | 9.11 |
| gemma3n-2.6B | GPU-accelerated | 69.84 | 2.48 |
| gemma3n-4.5B | CPU-only | 9.54 | 17.53 |
| gemma3n-4.5B | GPU-accelerated | 51.67 | 3.28 |
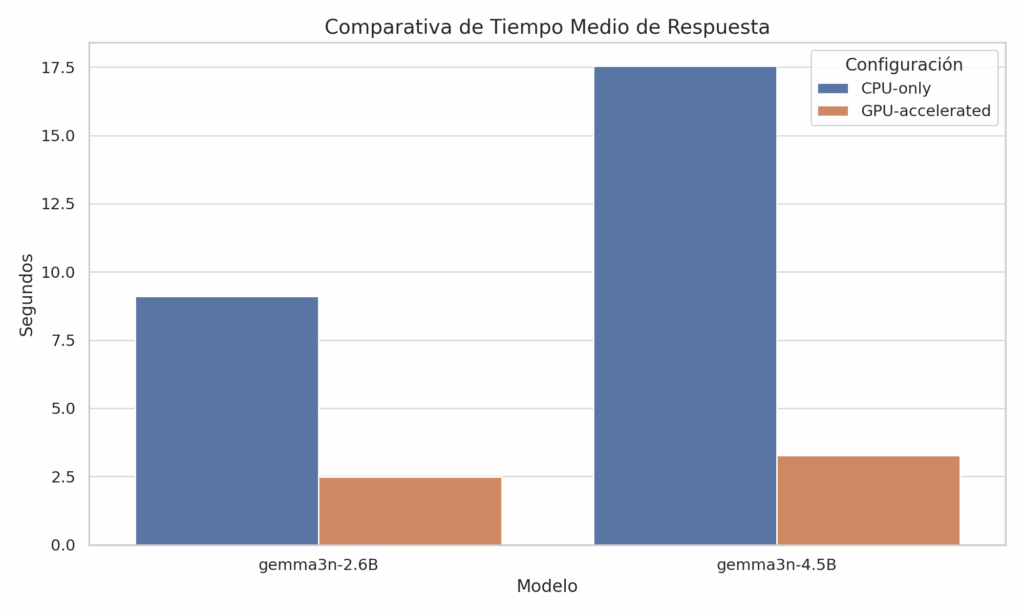
What does this mean in practice? A 500-word document is generated in 25-30 seconds with GPU, or 1-2 minutes with CPU alone. Perfectly usable speeds for real business work.
🏠 Your AI, in your home It runs entirely on your servers. Your customer data, confidential strategies and legal documents never leave your control. Zero risk of leakage, zero external dependency.
🌍 Speaks all the languages you need More than 140 native languages. If your company operates in international markets or handles documentation in several languages, this is pure gold.
📚 Photographic memory for large documents You can analyze up to 128,000 tokens at once. In practical terms: read entire contracts, 200-page technical manuals, or years of customer histories without losing context.
⚡ Efficient as a smartphone, powerful as a supercomputer We have found that it works perfectly from a basic laptop to industrial servers. In our tests, the difference between CPU and GPU is brutal: up to 3.5x faster with GPU acceleration. But even with CPU alone, the performance is more than sufficient for everyday business use.
Real-world testing in a business environment
We are not selling you smoke. These are the tests we did ourselves generating real corporate documents:
Successfully tested documents:
✅ Remote work policies for government agencies
✅ Budget proposals for IT upgrades
✅ Enterprise security incident reports
✅ Standard operating procedures
✅ Regulatory compliance memos
✅ Corporate procurement forms
Result: 100% of tests successful, with professional quality ready to use without additional editing.
What this means for your business (in concrete numbers)
Case in point: A consulting firm we serve was spending $3,200 per month on OpenAI APIs to process business proposals. With Gemma 3n implemented locally, that cost was reduced to zero. The implementation paid for itself in 2 months.
Another example: A law firm was manually processing 40 hours of contract analysis per week. With Gemma 3n trained on its own case law, that time was reduced to 4 hours. ROI of 900% in the first quarter.
We are talking about:
- Eliminate recurring costs of external APIs
- Reduce processing times by 80-90%.
- Maintain full control over critical information
- Scale without limits without paying more per use
Where can it revolutionize your business?
📄 Intelligent document automation Proposal genesis, contract analysis, automatic email classification. All processed locally, with the speed of a human expert but 24 hours a day.
🤖 Your private business assistant Trained specifically with your data, processes and terminology. Knows your business better than a senior employee, but never goes on vacation or makes mistakes due to fatigue.
🔍 Massive data analysis Process thousands of PDFs, emails or technical images in minutes. Perfect for due diligence, audits, or market research.
🔗 Real integration with your tools Thanks to function calling, you can connect directly with your CRM, ERP or any internal system. It’s like having a digital employee who knows how to use all your tools.
Why now is the perfect time
As you read this, your most astute competitors are already implementing local AI. Companies that move fast in this transition are going to have a brutal competitive advantage over the next 2-3 years.
The difference is that before you needed a team of PhDs in AI and months of development. Now you can have your solution up and running in weeks.
At Montevive.ai we are already implementing Gemma 3n for visionary companies that understand that the future of AI is private, controlled and profitable.
Actual technical requirements (tested by us)
For starters (Gemma 3n – 2.6B):
- 💻 Minimum: Server with 8GB RAM, modern processor
- ⚡ Recommended: Dedicated GPU for 3x speed increase
- 📈 Tested throughput: 20-70 tokens/second depending on configuration
For advanced cases (Gemma 3n – 4.5B):
- 💻 Minimum: Server with 16GB RAM
- ⚡ Recommended: Enterprise GPU for maximum performance
- 📈 Tested throughput: 10-52 tokens/second depending on configuration
No infrastructure? We can host it on our private servers while you set up your internal environment.
Are you ready to stop paying millions of dollars in bills for AI you don’t control?
The new generation of AI is here. And this time, it can be completely yours.
Do you have specific questions about how Gemma 3n can transform your industry? Write to us directly and our technical team will get back to you.
