At Montevive, we constantly face the challenge of optimizing costs in AI projects without compromising quality. After analyzing thousands of API calls and detecting waste patterns, we developed AutoCache: an intelligent proxy that automatically reduces Claude’s costs by up to 90%.
The problem we identified
While working with platforms like n8n, Flowise and Make.com, we discovered something frustrating: these tools do not support Anthropic prompt caching. This means that:
- Each call forwards the complete context (system prompts, tools, documentation).
- Users pay 10x more than necessary
- Latency is unnecessarily multiplied
Real example: A documentation chat with 8,000 tokens cost $0.024 per request. With smart caching, the same request costs $0.0066. Savings of 90%.
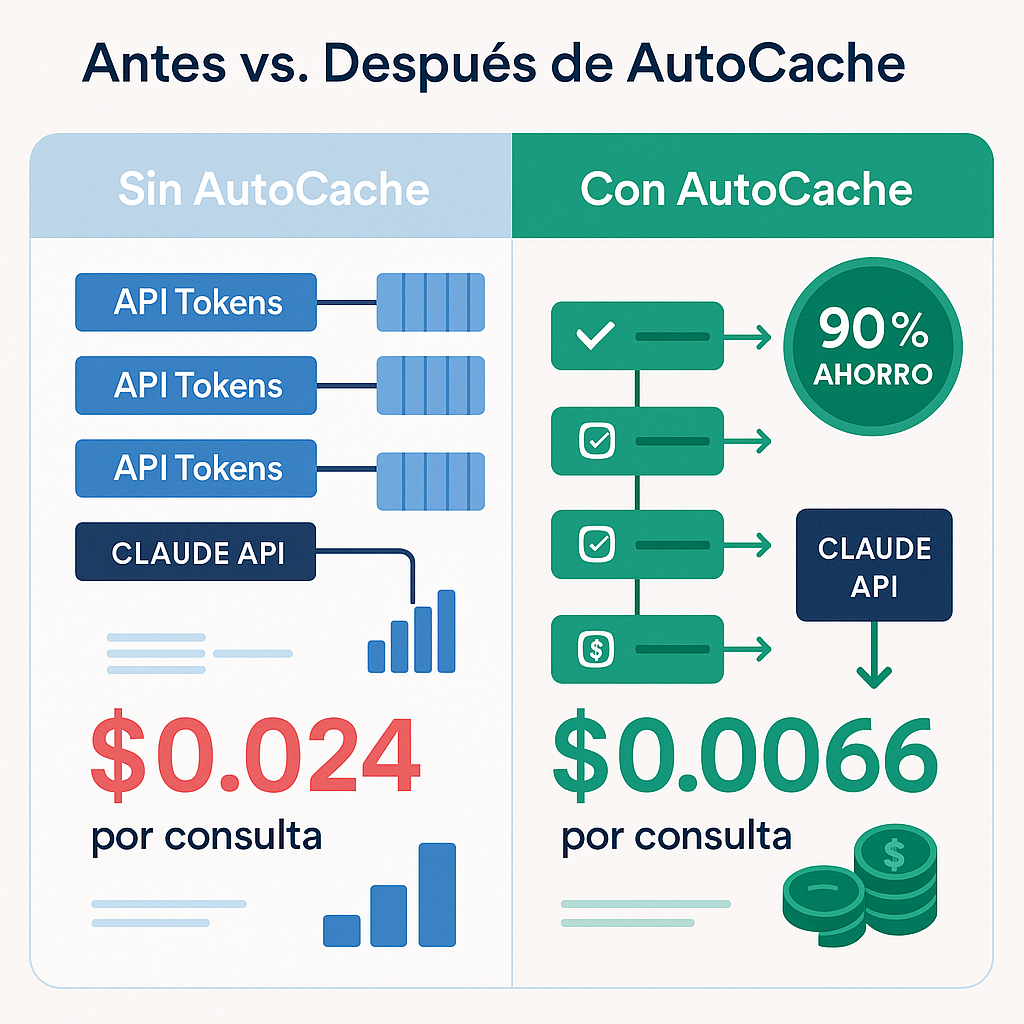
Our solution: Autocache
AutoCache is a transparent proxy that works as a drop-in replacement for Claude’s API. Zero code changes, maximum impact.
Key features
🧠 Smart Token Analysis
- Automatically identifies which parts of the prompt to cache
- Conservative, Moderate and Aggressive Strategies
- Up to 4 simultaneous cache breakpoints
📊 Real-Time ROI Analytics
- HTTP headers with detailed savings metrics
- Endpoint
/savingswith complete statistics - Automatic calculation of break-even point
⚡ Robust Architecture
- Developed in Go with modular architecture
- Full streaming and non-streaming support
- Docker-ready with docker-compose included
Real use cases with proven ROI
Technical documentation chat
- Typical request: 8,000 tokens (6,000 cached + 2,000 user input)
- Without AutoCache: $0.024/request
- With AutoCache: $0.0066/request(90% savings)
- Break-even: 2 requests
Code review assistant
- Typical request: 12,000 tokens (10,000 cached + 2,000 review)
- Without AutoCache: $0.036/request
- With AutoCache: $0.009/request(75% savings)
- Break-even: 1 request
Implementation in 5 minutes
git clone https://github.com/montevive/autocache
cd autocache
export ANTHROPIC_API_KEY="tu-api-key"
docker-compose up -dChange in your application:
// Antes: "https://api.anthropic.com/v1/messages"
// Después: "http://localhost:8080/v1/messages"That’s all! AutoCache starts optimizing automatically.
Impact on our operation
Since we implemented AutoCache in our internal projects:
- Cost reduction of 78% on average
- 65% latency improvement in repetitive context requests
- Full ROI transparency via automatic analytics
Development philosophy
At Montevive we believe that optimization should be invisible. Autocache reflects our philosophy:
- Zero-config default
- Automatic intelligence
- Total transparency in metrics
- Robust and scalable architecture
Next steps
AutoCache is open source and available at GitHub . We are working on:
- Web dashboard for advanced monitoring
- Support for more AI providers
- One-click integration with popular platforms
Do you want to reduce your AI costs by up to 90%? Try Autocache and share your experience with us.

